Despite the continuous hype around data analytics and the rapid acceleration of data technologies such as machine learning (ML) and artificial intelligence (AI), most companies are lagging behind with low data capabilities and no in-house data team in place. These companies have their data either fully unleveraged or marginally analyzed by executives on the side of their jobs to produce limited reports.
In such a situation, pushing the organization up the hill of data maturity would require building a team of data-specialized personnel. Building such a team can be daunting, as every company would have different conditions and no one way can fit all cases. However, covering the following main grounds can help cut miles on the road to building a data team from the ground up.
First, nurture the environment and plant the seeds. Data teams cannot grow in a vacuum. To prepare the organization to become data-driven with a data team, enhancing the organizational data culture is a good starting point. Having employees at all levels with a data-driven mentality and an understanding of the role of data analytics can significantly prepare the room for the planned team.
Second, connect with stakeholders and recognize priority needs. Carrying out data culture programs inside the organization can open up opportunities to have meaningful discussions with stakeholders on different levels about their data needs, what they already do with data, and what they want to achieve, in addition to having better insights into the pre-existing data assets. This is a good stage to recognize the organization’s data pain points, which would then be the immediate and strategic objectives of the future data team.
Third, define the initial structure of the team. According to the scale of the organization and the identified needs, data teams can have one of three main structures:
Centralized: This involves having all data roles within one team reporting to one head, chief data officer (CDO), or a similar role. All departments in the organization would request their needs from the team. This is a straightforward approach, especially for small-size companies, but can end up in a bottleneck if not scaled up continuously to meet the organization’s growing needs.
Decentralized: This requires disseminating all data roles and infusing them into departmental teams. This mainly aims to close the gap between technical analysis and business benefits as analysts in every team would be experts in their functional areas. However, the approach may lead to inconsistencies in data management and fragile data governance.
Hybrid: This consists of having governance, infrastructure, and data engineering roles within a core team, along with embedding data analysts, business analysts, and data scientists in departmental teams. The allocated personnel would report to the respective department head as well as the data team head. This approach combines the benefits of both centralized and decentralized structures and is usually applicable in large organizations as they require more headcount in their data teams.
Fourth, map the necessary tech stack and data roles. As the previous stages have uncovered the current uses and needs of data in an organization, it should be easier to start figuring out the tech tools that the team would be initially working with. Mapping the needed tech stack would be the first pillar before moving on to the hiring process. The second pillar would involve defining the roles that the team would need in its nascent stage to meet the prioritized objectives.
Several data job titles can be combined in a data team, with many of them having specializations that intersect with or bisect each other. However, there are three main role areas that should be considered for starting data teams:
Data engineering: implementing and managing data storage systems, integrating scattered datasets, and building pipelines to prepare data for analysis and reporting
Data analysis: performing final data preparation and extracting main insights to inform decision-making
Data science: building automated analysis and reporting systems, usually concerned with predictive and prescriptive machine learning models
Fifth, follow step-by-step team recruitment. Hiring new employees for the data team is one option. The other option can be upskilling existing employees with an interest in a data career and with minimum required skills. Even employees with just interest and no minimum required skills can be reskilled to fill some roles, especially within an initial data team.
The team does not need to take off with full wings. It can start small and gradually grow. Typically, data teams would start with data analysts who have extra skills in data engineering, data engineers who have experience with ad-hoc analyses and reporting, or a limited combination of both. In later stages, other titles can join onboard.
The baby-step-building approach is more convincing for stakeholders as it can be more efficient from a return-on-investment (ROI) perspective. Starting with a full-capacity team may end up being too costly for the organization, which could lead to the budding project being cut off in its prime.
Sixth, deliver ad-hoc analyses, heading towards long-term projects. In the beginning, data analytics experts at the organization would be expected to answer random requests and solve urgent data-related problems, like developing quick reports and reporting on-spot metrics. This is a good point to prove how data personnel can be of direct benefit to the organization.
However, along with delivering said ad-hoc requests, the data team should have strategic goals to enhance and develop the overall data maturity of the organization, like organizing, integrating, and automating the analytics processes and installing advanced predictive models. These long-term projects should foster the organization’s data maturity, which should result in ad-hoc requests being less frequent as all executives should be self-sufficient in using the installed automated reports and systems. In such a data-mature environment, the team would have time to advance their data products continuously, opening up new benefit opportunities.
Seventh, fortify the team’s presence. Strategic projects with shorter implementation periods and more immediate impact should be prioritized over longer ones, especially in the beginning. That would help continuously prove the benefits of the data team and the point of its foundation. Owning the products of the data team by having its name on it can help remind decision-makers of the team’s benefit. In addition, it is highly useful for the data team’s head to have access to top managerial levels to keep promoting the team’s presence and expansion.
Building a data team from scratch requires careful planning, investment, and commitment from organizational leadership. By following these guidelines and adapting them to their specific needs, organizations without prior data capabilities can establish a robust data team capable of driving innovation and offering a competitive advantage through data-driven insights.
The lifecycle of a Key Performance Indicator (KPI) is a dynamic process involving definition, recalibration, and—sometimes—abandonment. From establishment to practical application and ongoing evolution, KPIs undergo several steps to effectively measure performance, and prioritizing data reliability at every stage is crucial to achieving their intended purpose.
The foundation of reliable data
The first stage of the cycle, KPI selection, may seem simple, but it is a complex process intertwined with various interdependencies and calibrations with the organization’s objectives.
Establishing data reliability should start from this initial step, and involving employees as primary sources for KPI selection is an effective approach. Their valuable knowledge about the data generated from their activities enhances the reliability of the selected KPIs. Additionally, considering data availability and reliability as criteria for the selection further enhances overall data trustworthiness.
KPI documentation plays a pivotal role in ensuring reliability. Adopting a standardized documentation form establishes a solid foundation for rigorous and dependable data collection and reporting. This approach provides clear guidelines for defining KPIs, including unambiguous calculation formulas, ensuring that the collected data accurately reflects the intended purpose of each KPI.
Establishing dependable data collection
During the activation of KPIs, data reliability depends on the meticulous consideration of data sources, robust data-gathering methods, and the establishment of a strong governance structure. It is imperative to utilize trusted and verified data sources that are up-to-date, accurate, and aligned with the KPIs being measured. Accountability for KPI data should be established by clearly designating KPI owners and data custodians. Furthermore, adopting a standardized data collection process that incorporates technology-driven solutions significantly enhances accuracy.
Communicating meaningful insights
The analysis and reporting of KPIs are significant in ensuring the correct organization and communication of data to key stakeholders. Errors in data analysis have the potential to result in misleading insights, which can have negative effects on decision-making. Therefore, correctly identifying relevant KPI content and conveying meaningful insights derived from KPI data to various stakeholder groups within the organization is essential.
Continuous improvement
Finally, data reliability can be enhanced through the process of refreshing KPI documentation. This ongoing effort involves recalibrating KPIs after their initial establishment and customizing them for optimal use.
Attention is given to both the content of the KPIs and the standardization of their format. Standardizing KPI content establishes uniform guidelines and criteria for measurement and reporting, ensuring data reliability and consistency. This step refines the measurement and reporting processes, facilitating accurate and dependable data for decision-making purposes.
Monitoring KPI data reliability: The role of the Data Custodian
The Data Custodian is critical in upholding the reliability of data. They actively participate in the design of performance data collection, receipt and storage, processing, analysis, reporting, dissemination, and even archival or deletion of data. They implement measures to validate and verify the accuracy, consistency, and completeness of the data. This involves conducting regular data audits, resolving discrepancies or anomalies, and implementing data cleansing processes to ensure data integrity.
To evaluate the reliability of KPI data, the Data Custodian can monitor % KPIs with reliable data. This metric measures the number of reported KPIs that contain reliable and trustworthy content out of the total number of KPIs reported, according to smartKPIs.com.
In conclusion, to succeed in a data-driven world, organizations must prioritize data reliability along the KPI lifecycle. By implementing the strategies and practices discussed above, organizations can unlock the true potential of their performance measurement systems and empower stakeholders with reliable insights for better decision-making.
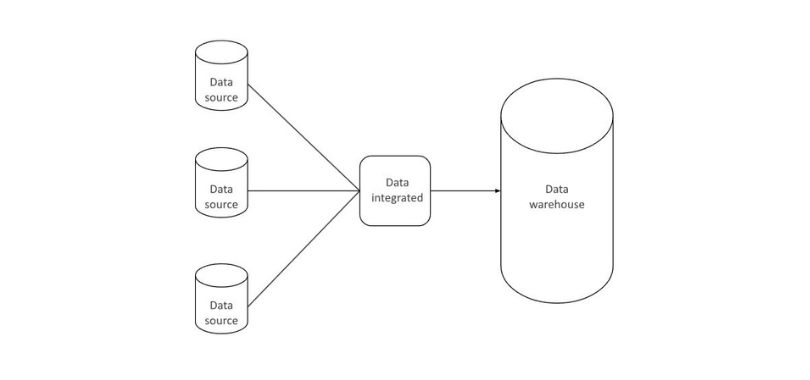
In today’s data-driven world, organizations are constantly grappling with an abundance of data coming from various sources and in different formats. Data integration has emerged as a critical process that enables businesses to connect these disparate data sources by consolidating them into repositories called data silos, creating a comprehensive and unified view of their information. This single source of truth empowers organizations to make more informed decisions and derive valuable insights for better business intelligence.
These disparate data sources can vary in type, structure, and format. Successful data integration finds a way to connect these sources, either by building relationships between them where they reside or by periodically extracting, transforming, and loading data (a process known as ETL) from these sources into one big database dubbed a data warehouse.
For example, when sales data is combined with customer data, the organization can gain a deeper understanding of customer behavior and preferences, which would allow personalized marketing efforts and improved customer satisfaction.
Data integration can be challenging as there is no one technical way of implementing it. Rather, the process depends on the needs and resources of each organization. Organizations with no technical capabilities would need to seek a third-party service provider.
Despite the variance across organizations, one thing remains consistent—every data integration process should be approached systematically by taking into consideration the following key strategic steps:
Defining integration goals: Organizations need to clearly outline the objectives and outcomes they want to achieve through data integration.
Assessment of data sources: This includes identifying all the data sources within the organization and understanding the structure, format, and quality of the data coming from each source.
Data mapping and transformation: This entails defining how different sources will be mapped to a common format. This may involve cleaning and preparing data silos in the first place.
Defining technique and tools: Based on the previous steps, a technical decision should be made on how to do the integration and the degree with which manual labor and automation will be utilized.
Building integration processes: This answers the question, “How will future data be integrated as well?” It involves defining workflows and processes that should be scalable, reliable, and capable of handling future data growth.
Testing and monitoring: As data integration is a continuous process, organizations should always test and monitor the integrated data thoroughly to ensure accuracy, consistency, and reliability. Validating the integration results should be done against predefined criteria, along with making necessary adjustments if discrepancies are found or to adapt to changing data sources and business needs.
In conclusion, data integration plays a crucial role in enabling organizations to harness the full potential of their data. By connecting disparate data sources and creating a single source of truth, organizations can unlock valuable insights, improve decision-making, and enhance operational efficiency. Following a systematic approach and leveraging appropriate integration tools lets organizations achieve successful data integration and gain a competitive edge in today’s data-driven landscape.
“If communication is more art than science, then it’s more sculpture than painting. While you’re adding to build your picture in painting, you’re chipping away at sculpting. And when you’re deciding on the insights to use, you’re chipping away everything you have to reveal the core key insights that will best achieve your purpose,” according to Craig Smith, McKinsey & Company’s client communication expert.
The same principle applies in the context of data visualization. Chipping away is important to not overdress data with complicated graphs, special effects, and excess colors. Data presentations with too many elements can confuse and overwhelm the audience.
Keep in mind that data must convey information. Allow data visualization elements to communicate and not to serve as a decoration. The simpler it is, the more accessible and understandable it is. “Less is more” as long as the visuals still convey the intended message.
Finding the parallel processes of exploratory and explanatory data visualization and the practice of sculpting could help improve how data visualization is done. How can chipping away truly add more clarity to data visualization?
Exploratory Visualization: Adding Lumps of Clay
Exploratory visualization is the phase where you are trying to understand the data yourself before deciding what interesting insights it might hold in its depths. You can hunt and polish these insights in the later stage before presenting them to your audience.
In this stage, you might end up creating maybe a hundred charts. You may create some of them to get a better sense of the statistical description of the data: means, medians, maximum and minimum values, and many more.
You can also recognize in exploratory if there are any interesting outliers and experience a few things to test relationships between different values. Out of the 100 hypotheses that you visually analyze to figure your way through the data in your hands, you may end up settling on two of them to work on and present to your audience.
In the parallel world of sculpting, artists do a similar thing. They start with an armature-like raw data in designing. Then, they continue to add up lumps of clay on it in exploratory visualizations.
Artists know for sure that a lot of this clay will end up out of the final sculpture. But they are aware that this accumulation of material is essential because it starts giving them a sense of ideal materialization. Also, adding enough material will ensure that they have plenty to work with when they begin shaping up their work.
In the exploratory stage, approaching data visualization as a form of sculpting may remind us to resist two common and fatal urges:
The urge to rush into the explanatory stage – Heading to the chipping away stage too early will lead to flawed results.
The urge to show all of what has been done in the exploratory stage to the audience, begrudging all the effort that we have put into it – When you feel that urge, remember that you don’t want to show your audience that big lump of clay; you want to show a beautified result.
Explanatory Visualization: Chipping Away the Unnecessary
Explanatory visualization is where you settle on the worth-reporting insights. You start polishing the visualizations to do what they are supposed to do, which is explaining or conveying the meaning at a glance.
The main goal of this stage is to ensure that there are no distractions in your visualization. Also, this stage makes sure that there are no unnecessary lumps of clay that hide the intended meaning or the envisioned shape.
In the explanatory stage, sculptors use various tools. But what they aim for is the same. They first begin furtherly shaping the basic form by taking away large amounts of material. It is to ensure they are on track. Then, they move to finer forming using more precise tools to carve in the shape features and others to add texture. The main question driving this stage for sculptors is, what uncovers the envisioned shape underneath?
In data visualization, you can try taking out each element in your visualization like titles, legends, labels, colors, and so on. Then, ask yourself the same question each time, does the visualization still convey its meaning?
If yes, keep that element out. If not, try to figure out what is missing and think of less distracting alternatives, if any. For example, do you have multiple categories that you need to name? Try using labels attached to data points instead of separate legends.
There are a lot of things that you can always take away to make your visualization less distracting and more oriented towards your goal. But to make the chipping away stage simpler, C there are five main things to consider according to Cole Nussbaumer Knaflic as cited in her well-known book, Storytelling with Data:
De-emphasize the chart title; to not drive more attention than it deserves
Remove chart border and gridlines
Send the x- and y-axis lines and labels to the background (Plus tip from me: Also consider completely taking them out)
Remove the variance in colors between the various data points
Label the data points directly
In the explanatory stage, approaching data visualization as a form of sculpting may remind us of how vital it is to keep chipping away the unnecessary parts to uncover what’s beneath, that what you intend to convey is not perfectly visible until you shape it up.
Overall, approaching data visualization as a form of sculpting may remind us of the true sole purpose of the practice and crystalize design in the best possible form.
Sign up for The KPI Institute’s Certified Data Visualization Professional course to learn the fundamentals of creating visual representations, the most effective layouts, channel selection, and reporting best practices.
Big data is a major asset for businesses that can access its insights. Making this happen, though, is a complicated job that needs the right tools. Enter data enrichment.
Understanding how it works and its impact on current industries is a great way to get to know what data enrichment can do for your organization. How it benefits the use of big data will become clearer, too.
What Is Data Enrichment?
Data enrichment is the process of identifying and adding information from different datasets, open or closed, to your primary data. Sources can be anything from a third-party database to online magazines or a social network’s records.
People and organizations use data enrichment to gather legitimate intel on specific things, like a customer, product, or list of competitors. And they can start with just their names or email addresses.
As a result, the original data becomes richer in information and more useful. You can find education trends, profitable news, evidence of fraud, or just a deeper understanding of users. This helps improve your conversion rate, customer relations, cybersecurity, and more.
The most popular method of making all this a reality is specialized software. Their algorithms vary in strengths and weaknesses, as SEON’s review of data enrichment tools shows. They can target human resources, underwriting, fraud, criminal investigations, and more. However, the goal is the same: to support the way we work and give us better insights.
Data Enrichment and Big Data: What Statistics Say
Data enrichment is a good answer to the problem of big data, which often sees masses of disorganized and sometimes inaccurate information that often needs cleaning, maintenance, and coordination.
Creating a data-driven culture within organizations
Despite the benefits of smart data management and major investments already in place, only 24% of firms have become data-driven, down from 37.8%. Also, only 29.2% of transformed businesses are reaching set outcomes.
What this shows is that, yes, big data is difficult to deal with but not impossible. It takes good planning and dedication to get it right.
There are several promising big data statistics on FinancesOnline. For starters, thanks to big data, businesses have seen their profits increase by 8-10%, while some brands using IoT saved $1 trillion by 2020.
Also, the four biggest benefits of data analytics are:
Faster innovation
Greater efficiency
More effective research and development
Better products and services
These achievements are taken further with data enrichment, which adds value to a company’s datasets, not just more information to help with decision-making.
How Does Data Enrichment Help Different Industries?
The positive impact of constructively managing data is clear in existing fields that thrive because of data enrichment and other techniques. Here are some examples.
Fraud Prevention
Data enrichment helps businesses avoid falling victim to fraudsters. It does this by gathering and presenting to fraud analysts plenty of information to identify genuine people and transactions.
For example, you can build a clear picture of a potential customer or partner based on information linked to their email address and phone number. Do they have any social media profiles? Are they registered on a paid or free domain? Have they been involved in data leaks in previous years? How old are those?
It’s then easier to make informed decisions because we know much more about how legitimate a user looks.
Banking services, from J.P. Morgan to PayPal, benefit from such intensive data analytics, as do brands in the fields of ecommerce, fintech, payments, online gaming, and more.
But so do online communities, where people create profiles and interact with others. For example, fake accounts are always a problem on LinkedIn, mainly countered through careful tracking of user activity. Data enrichment can help weed out suspicious users in such communities, keeping everyone else safe.
Marketing
Data enrichment in marketing tracks people’s activities and preferences through cookies, subscription forms, and other sources. To be exact, V12’s report on data-driven marketing reveals Adobe’s survey findings regarding what data is most valuable to marketers.
48% prefer CRM data
40% real-time data from analytics
38% analytics data from integrated channels
Companies collect this data and enrich it to create a more personalized experience for customers in terms of interactions, discounts, ads, etc. Additionally, brands can produce services and products tailored to people’s tastes.
HR
The more information your human resources department has, the better it’s able to recruit and deal with staff members. Data enrichment is a great way to build strong teams and keep them happy.
Starting from the hiring stage, data enrichment can use applicants’ primary data, available on their CVs, and grab additional details from other sources. Apart from filling in any blanks, you can flag suspicious applicants for further investigation or outright rejection.
As for team management, data enrichment can give you an idea of people’s performance, strengths, weaknesses, hobbies, and more. You can then help them improve or organize an event everyone will enjoy.
Summing Up
As we saw in these examples, data enrichment already contributes to the corporate world in different ways, both subtle and grand.
With the right knowledge and tools, we can tap into this wealth of information even further, allowing it to make a real difference in how we work and what we know, rather than simply amassing amorphous and vast amounts of data.
**********
About the Author
Gergo Varga has been fighting online fraud since 2009 at various companies – even co-founding his own anti-fraud startup. He’s the author of the Fraud Prevention Guide for Dummies – SEON Special edition. He currently works as the Senior Content Manager / Evangelist at SEON, using his industry knowledge to keep marketing sharp and communicating between the different departments to understand what’s happening on the frontlines of fraud detection. He lives in Budapest, Hungary, and is an avid reader of philosophy and history.